30. Substring with Concatenation of All Words(Solution)Leetcode题解
作者:PKUGoodSpeed
题目:
给定一个字符串,和一组单词,找出所有满足下面要求的子字符串(substring)开头的下标(index):
这些子字符串必须由给定那组单词串接组成,且每个单词在该子字符串中出现且仅出现一次。
For example, given:
s: "barfoothefoobarman"
words: ["foo", "bar"]
You should return the indices: [0,9].
Order does not matter.
思路:
最简单的方法就是枚举(Brute force),但时间复杂度是O(len(s)xlen(words)xlen(words[0])),我觉得会超时,这里就不讲了。有兴趣的读者可以自己试试,没准不会超时呢,反正我没试过。下面讲一定不会超时的方法。

代码如下,稍微注意一下边界条件。
class Solution {
public:
vector findSubstring(string s, vector& words) {
unordered_map ref;
vector ans;
for(auto s: words) ref[s] += 1;
int l = words[0].size(), n = s.size(), m = words.size();
for(int i=0;i cnt;
string buf, buf1;
bool ok = true;
while(j<=n-m*l && k<=n-l){
while(k<=n-l && k ref[buf]) break;
}
if(!ref.count(buf)) {
cnt.clear();
j = k = k+l;
}
else if(cnt[buf] > ref[buf]){
while((buf1 = s.substr(j, l)) != buf){
cnt[buf1]--;
j += l;
}
cnt[buf1]--;
j += l;
}
else{
ans.push_back(j);
cnt[s.substr(j,l)]--;
j += l;
}
}
}
return ans;
}
};
-
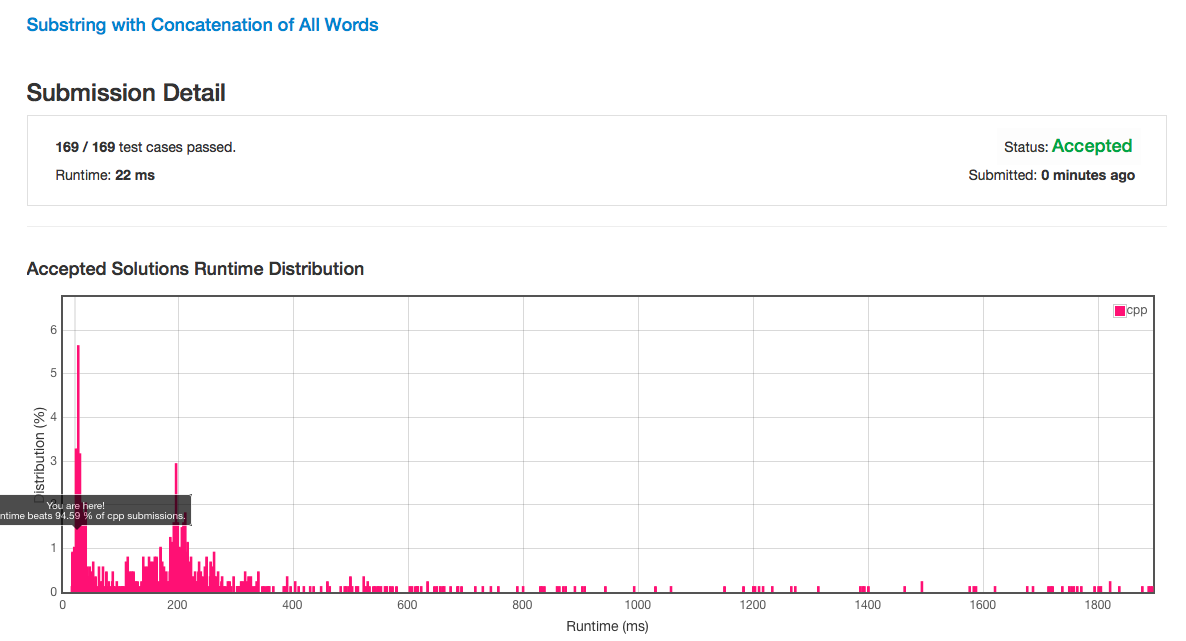
Performance 还可以:
-
方法#2:
自己做hash, 通过一些技巧,把hash function的计算缩小到O(1)复杂度,但是有一定的风险,就是hash function可能会冲突。
首先我们定义hash function如下:

class Solution {
const int K = 1000000007;
const int p = 199;
inline int add(const int&x, const int&y){
return (x+y)%K;
}
inline void add_to(int &x, const int&y){
x += y;
if(x >= K) x -= K;
}
inline int multiply(const int&x, const int &y){
return int((long(x)*y)%K);
}
inline int minus(const int&x, const int&y){
return (long(x) + K - y)%K;
}
int pwr(int n){
int x = p, ans = 1;
while(n){
if(n&1) ans = multiply(ans, x);
x = multiply(x, x);
n >>= 1;
}
return ans;
}
public:
vector findSubstring(string s, vector& words) {
int n = s.size(), m = words.size(), l = words[0].size();
int factor = pwr(l);
unordered_map ref;
for(auto str: words){
int tmp = 0;
for(int j=l-1; j>=0; --j){
tmp = multiply(tmp, p);
tmp += (int)str[j];
}
ref[tmp] += 1;
}
vector hash(n + 1, 0), ans;
for(int j=n-1; j>=0; --j){
hash[j] = multiply(hash[j+1], p);
hash[j] += (int)s[j];
}
for(int i=0;i cnt;
int buf1, buf2;
bool ok = true;
while(j<=n-m*l && k<=n-l){
while(k<=n-l && k ref[buf1]) break;
}
if(!ref.count(buf1)) {
cnt.clear();
j = k = k+l;
}
else if(cnt[buf1] > ref[buf1]){
while((buf2 = minus(hash[j], multiply(hash[j+l], factor))) != buf1){
cnt[buf2]--;
j += l;
}
cnt[buf2]--;
j += l;
}
else{
ans.push_back(j);
cnt[minus(hash[j], multiply(hash[j+l], factor))]--;
j += l;
}
}
}
return ans;
}
};
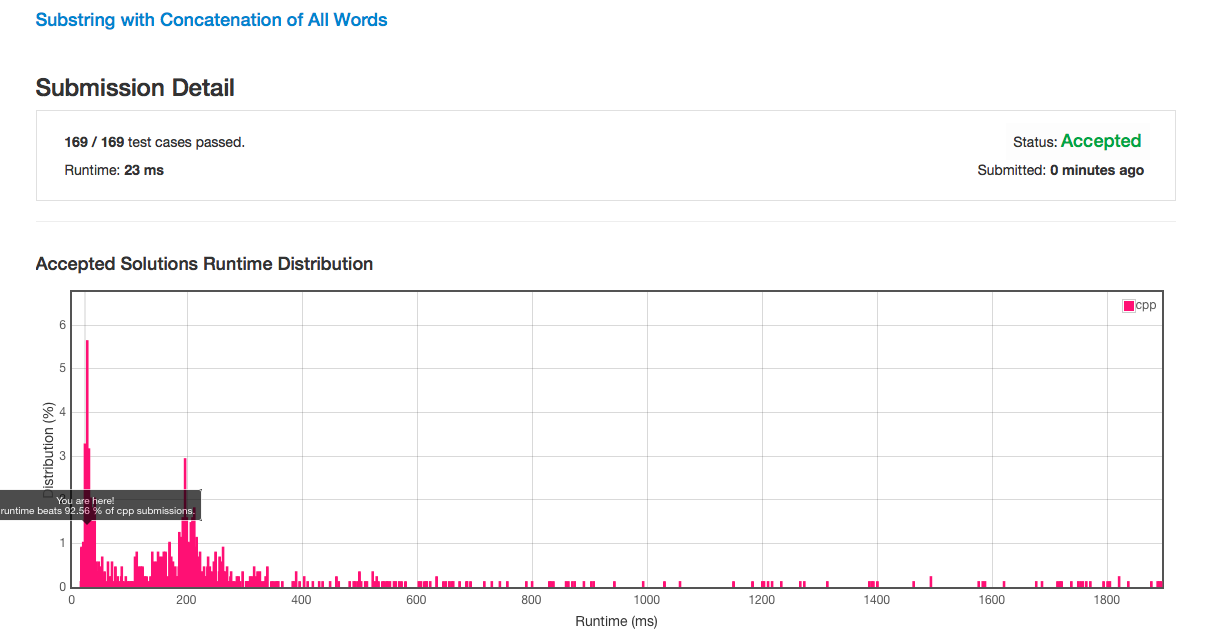
- Performance 如下 (当每个单词长度很大的时候,速度提升应该会比较快)